
引言
Push通知是电商移动应用的必备功能,也是电商营销的一个重要组成部分。对于用户,push相当于是一个小助手,向用户汇报订单进度,或者为用户推送其可能会感兴趣的商品、活动等促销信息;对于电商平台,push是一种低成本且有效的用户召回手段,可以起到拉新、促活、留存等作用。
随着互联网、人工智能、机器学习技术的发展,“精准营销”已经成为营销的一种趋势,个性化push便是其中一个落地场景,如下图所示。个性化push与经典的推荐任务有许多的不同,主要体现在以下几个方面:
- 平台主动推送,用户此时往往不在站内,没有明确的意图信息(比如搜索、正在浏览的商品等),且push发送时刻等因素也会影响push的点开率。
- 推送频率受限,为防对用户的骚扰,一段时间内只能发送一条push。
- 内容展示受限,一条营销push的文案往往只能包含一到两个商品或活动信息。
- 文案影响,简洁、有吸引力的文案对用户决定是否点开push的影响往往很大。
本文主要讨论活动营销push场景的算法改进。该场景的主要目的是将正在参加促销活动(如直降、限时购、税费补贴)的商品信息推送给用户,且通过算法筛选出用户最有可能购买的商品。

个性化Push点击率预估问题
为了更好地实现个性化push,用算法进行点击率预估是一个关键环节。注意这里的点击率预估和互联网广告的CTR预估有些不同,这里将问题转化为预估用户对商品的偏好,然后结合业务规则筛选出最有可能成交的用户-商品对,再落实到营销push中去。
目前我司个性化push主要应用在活动商品提醒等场景,所覆盖的营销场景还不多;特征以较粗粒度的统计特征为主,特征工程还不够完善;算法模型主要是Spark MLlib提供的Logistic Regression和Random Forests,因此我们可以从如下几个方面入手开展工作:
- 覆盖更多的营销场景
- 完善特征工程,提高基础特征覆盖度
- 引入学习能力更强的机器学习模型,自动构造表达能力较强的组合特征和高阶特征
本文即介绍我们最近在第三个方面的尝试,考虑到开发效率,我们先尝试了业界已经证实有效的模型:GBDT+LR。
GBDT+LR模型简介
GBDT+LR的模型框架最初由Facebook公司于2014年在一篇论文Practical Lessons from Predicting Clicks on Ads at Facebook中提出,它相当于是一种组合模型,由两种较为基础的模型串联构成:GBDT和LR。下面先分别简要介绍一下这两个模型,然后介绍对它们进行组合的目的。
关于LR和GBDT
LR全称Logistic Regression,是CTR预估最经典的模型。LR的模型结构非常简单,本质上是一个线性模型,只不过经过了logit变换将输出值映射到[0,1]区间,这样可以对应上点击率的物理意义,看下图便知(图片出处)。
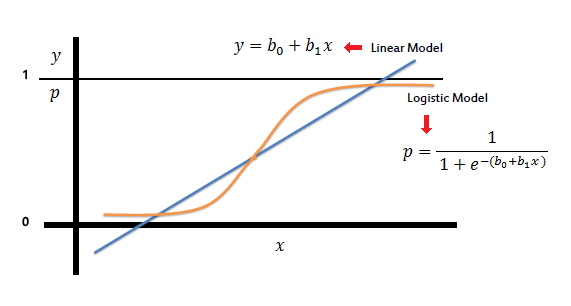
LR是最成熟,也是业界使用最广泛的模型,有诸多优点——简单、可解释、易大规模并行(其分布式优化算法SGD、LBFGS已经很成熟)、线上预测速度快;与之相对的,不足也很明显:如果使用LR,那么就必须要做大量的特征工程。LR本身并不“智能”,其预测能力完全取决于特征的丰富度,其中特征的处理、选择、组合等,都依赖人工经验,费时吃力且不一定有效。
再来说GBDT,全称Gradient Boosting Decision Tree,也是非常经典的统计学习模型,它是一种非参数学习模型,能较好地拟合非线性。其基于集成学习的Boosting思想,基本过程是迭代地计算出一系列简单决策树,其中后一棵树用于拟合它前面所有树的残差。如下图所示的例子(图片出处),第一棵树tree1已经能较好地拟合数据的模式,但还比较粗糙,第二棵树tree2就去拟合这种误差,然后tree3进一步拟合tree2导致的误差,如此进行下去,逐步精细。
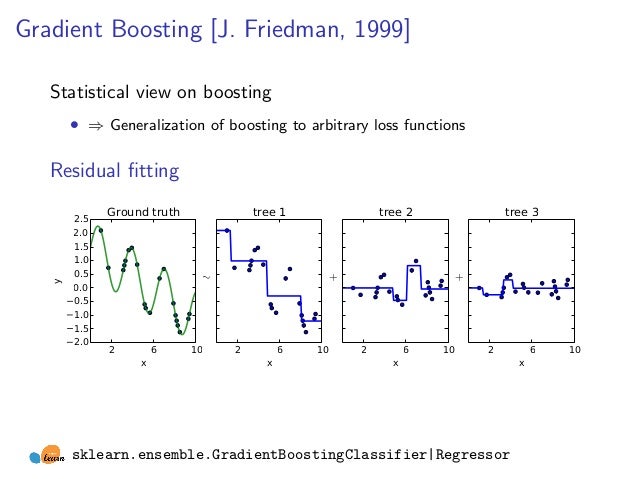
GBDT最显著的优点是学习能力强、可解释性好,能拟合数据中复杂的非线性模式,且擅长处理连续型特征,相比于LR/SVM等模型,降低了人工处理特征的工作量;缺点则是由于模型复杂度的提高,会导致计算复杂度的提高,比LR消耗更多的计算资源。
用GBDT做特征组合
GBDT的基模型是单棵CART决策树,其原理使得它能发现特征的相对重要度,并进行自动特征组合——从根节点到叶子节点的一条路径即是一组用多个特征对样本进行判别的规则,不同类别的样本通过GBDT往往会激活不同的叶子节点集,因此样本所激活的叶子节点的分布情况就可以视为一种特征的组合。
于是,自然地就有这样的想法:将GBDT模型本身用作一种特征的“组合器”,用它自动构造有效的特征组合,然后再将这些特征输入简单分类器(比如LR等)执行最终的分类任务。如下图所示(图片出处),一个样本通过GBDT每一棵树,都会落在一个叶子节点上,将这样的叶子节点标记为1,其他的叶子节点标记为0,所有叶子节点的标记就构成了一个有序的0-1序列,它可视为对组合特征的一种编码。因此,GBDT有多少个叶子节点,生成的组合特征就有多少维,通常GBDT基模型的数量不会很多,大概在几百至几千的量级,且由于其boosting的原理,基模型树都是浅层树,通常在2~3层,单棵树的叶子节点数量通常也基本在个位数,因此经过编码的特征向量维度是随迭代次数线性增长的。
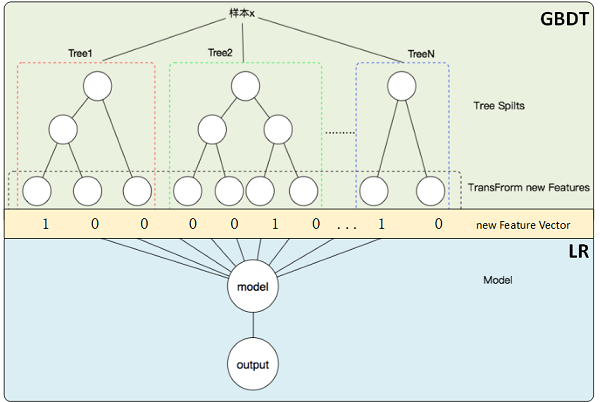
特征和模型训练
关于特征抽取。虽说业界没有标准化的特征抽取方法,主要基于数仓可以获得的数据,依据业务经验进行特征抽取,但对于一些统计类特征的设计,是可以总结出一些模式的:
在某个时间窗口内,针对某些对象(用户、商品)在某些维度(页面类型、类目、品牌、活动等)上的可度量行为(浏览、收藏、加购、下单)设计统计指标(次数、占比等)。
比如,近10天用户浏览美妆类目商品详情页的次数占所有浏览次数的比重,该特征反应了用户近期对美妆类目的兴趣偏好;又如,近5天商品在参加活动过程中被加购的次数,该特征则反映了某一参加活动的商品的热销程度。
关于模型训练。其一是模型的实现,由于GBDT和LR这两种模型Spark都有提供,因此在它们基础上开发可以省去不少功夫。其二是正负样本构造,如果用户点击push后在未来7天购买了所推送的商品,则为正样本,否则为负样本。用户-商品对来自于近30天有过行为的用户集合与商品集合的笛卡尔积,即用户群体是近30天有行为的用户,对每个用户召回的商品是近30天被浏览、购买过的商品,这么构造用户-商品对的原因是在push活动营销场景下,我们更希望通过push推送的商品能直接促成交易,将用户拉回app、促活并不是首要目的,因此直觉上给用户推送其之前看过的商品或者正在犹豫是否购买的商品,加上活动营销的利益点,更容易让用户理解推送的缘由。
筛选的训练数据集中,正样本有47万条,负样本约有3.3亿条,正负样本严重不均衡。直接拿这么多样本喂给GBDT+LR模型会使得训练时间很长,一个经济有效的方法是对负样本做降采样,使得正负样本的数量级相差不过大,常用的经验是1:10到1:20,下面的代码给出了降采样的一个例子:
import spark.implicits._
val trainDatasetP = trainDataset.filter($"label"===1) // 提取出正样本
val trainDatasetN = trainDataset.filter($"label"===0) // 对负样本降采样
.sample(withReplacement = false, fraction = 0.02, seed = 42)
trainDataset0 = trainDatasetP.union(trainDatasetN).orderBy(rand()) // 构造新的训练数据集
最终,我们将GBDT构造的特征与原始特征拼接在一起进行训练(如果只用GBDT特征效果会较差),特征维度约1200维,正负样本比控制在1:15左右,GBDT迭代20轮,基模型树的最大深度为5,步长0.1,LR迭代100轮,带L1和L2惩罚,提交到YARN集群上约1小时可以完成训练(训练时长不具有参考性,与集群资源量有关)。测试集有约4亿条样本,没有做降采样,离线训练的模型在测试集上的AUC是0.8866,在同一个测试集上比原来的RF模型提高了2.7%。
线上应用及效果评估
业务逻辑。业务的出发点是将用户最感兴趣的商品参加的活动信息(优惠折扣、补贴等)通知给用户,提高活动营销的成交额。可以看作是对每个用户,搜索<用户,商品,活动>这个三元组的最佳组合。然而直接优化该问题比较复杂,我们将问题分解为去分别优化<用户,商品>和<商品,活动>这两个子问题,前一个子问题可以转化为user-item级的购买预测问题,后一个子问题可以转化为搜索商品在哪个活动中的折扣力度更大。这样分解的原因在于,用户的主要目的还是购买商品,而不是参加某个活动(虽然用户可能对不同活动的偏好程度不同);另一个好处是两个子问题相对独立,实现了解耦。
数据端须要处理的过滤规则主要有如下几个方面:
- 购买过滤
- 使用周期:用户在一段时间内购买过末级类目下的某个商品。(复购逻辑:用户购买间隔/前一次购买件数)
- 用户体验:用户购买未成功(未支付、关单、但未包括退款退货)
- 推送过滤
- 用户新鲜度:近3天有过推送的商品
- 3天内,不同给用户推送相同的文案(活动类型)
下图是核心业务逻辑的流程图:

线上产品形态。算法应用的主要过程是通过模型为用户-商品对打分,然后结合业务规则(比如去掉近期购买过和已经推过的商品)过滤出最有可能成交的topN个用户-商品对,写入活动营销接口表中,再通过营销系统将个性化push投放出去。用户点击push即直接导入相应的商品详情页或weex搭建的个性化活动落地页,如下图所示,落地页上焦点区域展示push中推送的商品,下方区域是一排三的商品缩略图展示,前排主要是算法筛选出用户成交概率较高的活动商品,后排有根据其他业务规则的选品。
值得一提的是,实验发现push导入到落地页并不比导入商品详情页好多少,可能的原因是导入落地页增加了用户浏览选择的环节,这相当于增加了一层漏斗。
模型上线后的效果。为了验证模型的效果,我们设计了线上A/B测试,并对活动营销push的点击率、商品祥情页到达率、点击转化率和发送转化率这几个核心指标跟踪观察了一段时间,如下图所示。



- 点击率:点击push的用户数 / 投放的用户数
- 点击转化率:点击push后购买所推送商品的用户数 / 点击push的用户数
- 发送转化率:点击push后购买所推送商品的用户数 / 投放的用户数
其中对照组(v2)是baseline模型即之前线上的RF模型,实验组(v4)是GBDT+LR模型。可见,在四个指标上,GBDT+LR的效果都有显著的提升——相比对照组,实验组点击率平均提升6.43%, 点击转化率平均提升7.59%, 发送转化率平均提升14.53%.
GBDT+LR的局限性
GBDT+LR能取代特征工程,真正地解放特征交叉、组合、高阶特征设计这些过程吗?笔者认为并不能。主要原因是GBDT模型的结构并不是为了特征组合而专门设计的,只是它的基模型——决策树的天然结构使其恰好有类似于特征组合的功能,于是就将其拿来做这项工作。此外,它构造组合特征的形式比较单一:贪心地以最小化平方误差或基尼指数的方式构造决策路径,并以其对应的一组分支规则形成特征组合,这实际上并没有解决二阶乃至高阶特征交叉的问题,且对稀疏特征的学习能力较弱。因此在后续的迭代中,我们将尽快跟进FM/FFM, GBDT+FM, DNN, Wide & Deep等特征组合能力更强的模型。此外,须要指出的是,对于push的点击,除了推送商品的选择,文案本身也是一个重要的因素,着手优化文案是另一个值得尝试的工作。
参考
- Facebook Inc, Practical Lessons from Predicting Clicks on Ads at Facebook
- 玉心sober, CTR预估中GBDT与LR融合方案
- Prince Grover, Gradient Boosting from scratch
- 解密阿里妈妈“AI 智能文案”:1 秒钟 20000 条背后的奥妙