
经典排序算法小结
比较弱的排序算法
选择排序 (Selection Sort)
思想:扫描一次数组,我们就能得到最小值,把这个最小值取出,再扫描剩下的元素,就能得到第二小的值,以此类推。
设数组是A[0...n-1]
- 扫描
A[0...n-1],选出最小的,与A[0]交换,A[0]已经有序; - 扫描
A[1...n-1],选出最小的,与A[1]交换,A[0...1]已经有序; - 扫描
A[2...n-1],选出最小的,与A[2]交换,A[0...2]已经有序; - …
- 扫描
A[n-2...n-1],选出最小的,与A[n-2]交换,A[0...n-2]已经有序; - 整个数组已经有序
Notes: 一共扫描了
n-1次,每一次扫描的范围都会减少一,总比较次数为n*(n-1)/2;最多做n-1次交换(选择排序的交换次数最少)。
- 时间复杂度:$O(n^2)$
- 为数不多的优点:原地排序
- 实际场景下几乎不使用
参考代码(C++):
template<typename T>
void SelectionSort(vector<T>& A) {
int n = A.size();
// 扫描n-1次
for (int i = 0; i < n - 1; ++i) {
int pos_min = i; // 最小值的位置
for (int j = i; j < n; ++j) {
if (A[j] < A[pos_min]) {
pos_min = j;
}
}
std::swap(A[i], A[pos_min]);
}
}
冒泡排序 (Bubble Sort)
思想:我有强迫症,看到这里有一对数字不是有序的,我就交换它们!又发现了一对,再交换…终于没有不是有序的数对了~
设数组是A[0...n-1]
- 考察
A[0]和A[1],A[1]和A[2]…A[n-2]和A[n-1],如果不是有序就交换,这一轮考察结束后,最大的已经被交换(冒泡)到A[n-1]; - 考察
A[0]和A[1],A[1]和A[2]…A[n-3]和A[n-2],如果不是有序就交换,这一轮考察结束后,第2大的已经被交换(冒泡)到A[n-2]; - …
- 考察
A[0]和A[1],如果不是有序就交换,这一轮考察结束后,第n-1大的已经被交换(冒泡)到A[1]; - 整个数组已经有序
Notes: 一共考察了
n-1轮,每一轮考察的范围都会减少1,总比较次数为n*(n-1)/2;最多做n*(n-1)/2次交换(交换次数太多了)。
- 时间复杂度:$O(n^2)$
- 也属于排序的入门级算法
参考代码(C++):
template<typename T>
void BubbleSort(vector<T>& A) {
int n = A.size();
// 考察n-1轮
for (int i = 0; i < n - 1; ++i) {
for (int j = 0; j < n-1-i; ++j) { // 这一轮要考察的部分
if (A[j] > A[j+1]) { // 每次考察相邻的一对
std::swap(A[j], A[j+1]);
}
}
}
}
下面开始,是实用的排序算法。
插入排序 (Insertion Sort)
插排的原理就类似于抓扑克牌,每次摸一张牌,然后把它插入之前已经有序的牌中。
插入排序的具体做法如下:
- 从第2个元素开始(第1个元素已经有序),在已经有序的序列中从右往左走,如果当前位置元素大于待插入元素,就将其往右挪一位,直到走到数组头部或者走到第一个小于等于待插入元素的位置,将待插入元素挪到到该位置之后;
- 取出下一个元素(未排序的序列),重复上面的步骤,直到整个序列处理完。

- 插排的性能总体而言是比较好的,尤其在数组
近似有序的时候,因为每个元素平均移动的次数将比较少。 - 虽然最坏时间复杂度是$O(n^2)$(数组完全逆序),但是最佳时间复杂度是$O(n)$(数组完全有序)。
- 在
STL中,sort内部的算法中在排序的后期使用了插排。
参考代码(C++):
template<typename T>
void InsertionSort(vector<T>& A) {
int n = A.size();
for (int i = 1; i < n; ++i) {
T temp = std::move(A[i]);
int j;
for (j = i; j > 0 && temp < A[j-1]; --j) {
A[j] = std::move(A[j-1]);
}
A[j] = std::move(temp);
}
}
堆排序 (Heap Sort)
基本思想:建堆,之后利用堆的性质不断取出最大/最小值,同时维护堆性。
- 高效实用的排序算法
- 建堆的平摊时间复杂度是
O(n),取出最值O(1),维护堆性O(logn),因此堆排序的时间复杂度是$O(n \log n)$,且无须额外空间
template<typename T>
void HeapSort(vector<T>& A) {
int n = A.size();
/**
* 第一步:将数组堆化(这里是建最大堆)
* 从第一个非叶子节点开始执行SiftDown操作
* begin_idx: 第一个非叶子节点的位置
* 如果堆顶从0开始,那么一个节点j的父节点是(j-1)/2
*/
int begin_idx = n / 2 - 1; // (n-1 - 1) / 2 = n/2 - 1
for (int i = begin_idx; i >= 0; --i) {
SiftDown(A, i, n);
}
/**
* 第二步:对堆化数据排序
*/
for (int i = n - 1; i > 0; --i) {
std::swap(A[0], A[i]); // 等价于:取出堆顶,与最后一个节点交换
SiftDown(A, 0, i); // 维持堆性,这时堆的size = i
}
}
SiftDown是非常关键的操作:
template<typename T>
void SiftDown(vector<T>& A, int i, int n) {
/**
* 对位置i处的节点做SiftDown(最大堆)
* n: 当前堆的有效size
*/
T tmp = std::move(A[i]);
int child;
for (; 2*i+1 < n; i = child) { // 循环条件是左孩子存在
int lchild = 2*i + 1, rchild = lchild + 1;
child = lchild;
if (rchild < n && A[rchild] > A[lchild]) { // 选择左右孩子中较大的
child = rchild;
}
if (tmp < A[child]) {
A[i] = std::move(A[child]);
} else break;
}
A[i] = std::move(tmp);
}
归并排序 (Merge Sort)
基本思想:Divide & Conquer
- 把数组一分为二,分为长度大致相等的左、右两个子数组
- 分别对左、右子数组进行排序
- 左右子数组有序后,合并它们
- 处理左、右子数组时,递归地进行

归并排序的递归方程: \(T(n) = 2 T\left(\frac{n}{2}\right) + O(n)\) $T(n)$表示对整个数组进行排序的时间,$2T\left(\frac{n}{2}\right)$表示对两个子数组进行排序的时间,而$O(n)$表示合并两个子数组的时间复杂度。求解这个递归方程,得到$T(n) = O(n\log{n})$。
关于时间复杂度,也可以这么简单地理解:划分原问题为更小规模子问题的复杂度是$O(\log{n})$(其实是个递归树,而且这里是二叉树),合并已排好序的数组的复杂度是$O(n)$,因而是$O(n\log{n})$。
参考程序(C++):
首先是排序入口:
template<typename T>
void MergeSort(vector<T>& A, int start, int end) {
if (start >= end) return;
int mid = start + (end - start) / 2;
MergeSort(A, start, mid);
MergeSort(A, mid+1, end);
Merge(A, start, mid, end);
}
然后是合并排序数组的操作:
template<typename T>
void Merge(vector<T>& A, int start, int mid, int end) {
vector<T> helper(end-start+1); // 临时开辟辅助数组(在外部预先申请好空间可以提高效率)
int p = start, q = mid+1, k = 0;
while (p <= mid && q <= end) {
if (A[p] < A[q]) helper[k++] = A[p++];
else helper[k++] = A[q++];
}
while (p <= mid) helper[k++] = A[p++];
while (q <= end) helper[k++] = A[q++];
std::copy(helper.begin(), helper.end(), A.begin()+start); // 拷贝回原数组(大数据比快排慢的主要原因)
}
快速排序 (Quick Sort)
我喜欢把快排称为「划分排序」(Partition Sort),因为这是其工作原理所在。至于为什么叫「快排」,顾名思义,因为快嘛——它是目前在实际应用中表现最好的算法之一(虽然平均意义上的时间复杂度依然是$O(n \log n)$)。
快排和归并排序可以说是一对「姐妹算法」,体现了正向思维和逆向思维的联系。快排的基本思想是先让数组整体有序,再对局部进行递归操作。而归并排序是先局部有序,然后通过合并有序的局部来构造有序的整体。
总体步骤:
- 如果数组只有1个元素,不做任何操作,返回
- 选取一个主元(pivot),对原数组进行划分(partition)。通常的做法是以pivot为分界点将数组分为两部分,使得左边的元素都小于pivot,右边的元素都不小于pivot。
- 分别对左、右两部分进行排序
可以在HackerRank练习,那里的教程写得比较详细。先练习Partition的实现,再练习整个排序的递归实现。后面还有复杂度的讲解。基本上认真做一遍,就能很好地理解快排了~
关于快排的复杂度分析,这里就不搬运了,CLRS上有详细的推导。
通常Partition的实现是「就地」(in-place)进行的,因为这样可以避免额外的空间开销,从而提高效率。Partition的写法不止一种,往往Pivot的选取不同,Partition的方式也不同。这里给出一种被称为Lomuto Partitioning的划分方法,它选取子数组的最后一个元素作为Pivot,然后用一个变量fstLarger记录第一个比Pivot大的元素位置,它初始化为第一个元素的下标。当往右遍历子数组时,如果遇到了比Pivot小的元素,就将该元素与fstLarger处的元素交换,之后fstLarger往右移一位。还是看图比较直观:
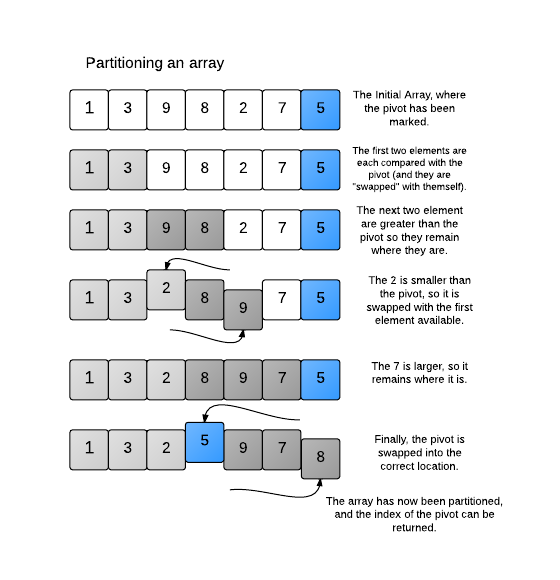
template<typename T>
int Partition(vector<T>& A, int low, int high) {
int pivot = A[high];
int fstLargerPos = low;
for (int i = low; i < high; ++i) {
if (A[i] < pivot) {
swap(A[i], A[fstLargerPos]);
fstLargerPos++;
}
}
std::swap(A[high], A[fstLargerPos]);
return fstLargerPos;
}
最后返回Pivot所在的位置,Pivot直到整个排序结束都不会改变了,它已经处于「正确」的位置上。这个返回值也是划分的依据,它将决定左、右子数组的长度。于是,快排主体的递归写法如下(还是很简洁的~):
template<typename T>
void QuickSort(vector<T>& A, int low, int high) {
if (low >= high) return;
int mid = Partition(A, low, high);
QuickSort(A, low, mid-1);
QuickSort(A, mid+1, high);
}